머신러닝 전 꼭 알고 가자! - 카테고리컬 데이터를 처리하는 방법 : 레이블 인코딩, 원 핫 인코딩(sklearn 라이브러리와 Pandas 라이브러리 이용 방법)

카테고리컬 데이터는 수치일 때도 있겠지만 문자열인 경우가 훨씬 많을 것이다.
이 때 컴퓨터는 모든 데이터를 수치로만 처리할 수 있기 때문에 문자열 데이터를 처리해주는 과정을 거쳐야한다.
이 때 사용하는 인코딩 방식에는
LableEncoding 과 One Hot Encoding 2가지가 있다.
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
from sklearn.compose import ColumnTransformer
# 1. 레이블 인코딩 하는 방법
encoder = LabelEncoder()
encoder.fit_transform(X['Food Name'])
LableEncoding 은 각 문자열 데이터에 숫자로 대신 표현을 하여 1대1 대응시키도록 처리해주는 과정을 뜻한다.
위 이미지로 예를 들면 apple 은 1, Chicken은 2 이런 식으로 표현하는 것이다.
이 인코딩의 단점은 카테고리컬 데이터가 3개 이상이 되면 인공지능이 학습할 때에 학습이 원활하지 않다는 것이다.
그래서 LableEncoding은 카테고리컬 데이터가 2개 이하일 때 사용하는 것을 추천한다.
이러해서 카테고리컬 데이터가 3개 이상일 경우엔 아래 One Hot Encoding 을 이용한다.
# 원 핫 인코딩 하는 방법
# [0] 이라고 쓴 이유는 X에서 원핫인코딩할 컬럼이
# 컴퓨터가 매기는 인덱스가 0 이기 때문에
# 즉, 원핫인코딩할 컬럼의 인덱스를 써주면, 변환시켜준다.
# 만약 원핫 인코딩할 컬럼이 2개면, 해당 컬럼의 인덱스를 리스트안에
# 적어주면된다.
ct = ColumnTransformer( [ ('encoder',OneHotEncoder(), [0] ) ] ,
remainder='passthrough' )
# remainder = 'passthrough' 는 내가 지정한 컬럼 외에는 건들지 말라는 뜻이다.
# 결과는, 원핫 인코딩한 컬럼이, 행렬의 맨 왼쪽에 나온다.
X = ct.fit_transform(X)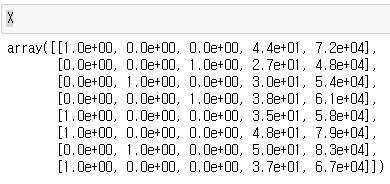
원리는 데이터의 문자열 이름을 컬럼으로 올리고 해당 데이터를 선택할 때엔
해당 컬럼과 데이터의 위치에서 0, 1로 표시하는 것이다. 1이면 해당 데이터를 말하고 있는 것.
위 함수를 이용할 때 주의할 점은 remainder ='passthrough' 를 신경써야한다는 것이다.
이 파라미터 값이 없다면 지정한 컬럼 외에도 데이터가 변경될 수 있다.
위 결과 이미지를 보면 처리된 컬럼은 1 과 0 으로만 이루어진 것을 볼 수 있다.
이러한 과정을 전처리 과정이라고 한다.
이 과정을 끝마치면 인공지능 학습시킬 데이터가 준비된 것이다.