머신러닝/머신러닝 라이브러리
머신러닝의 종류 (3) - K-NN ( K- Nearest neighbor )
Cong_S
2022. 5. 6. 17:06

K-NN 유형도 데이터의 분류를 위한 인공지능의 유형이다.
다만 그 방식에서 차이가 있는데 0과 1이 아닌
레이블링된 데이터의 위치가 어느 쪽 데이터들과 더 가깝느냐의 차이로 분류가 이루어지게 된다.
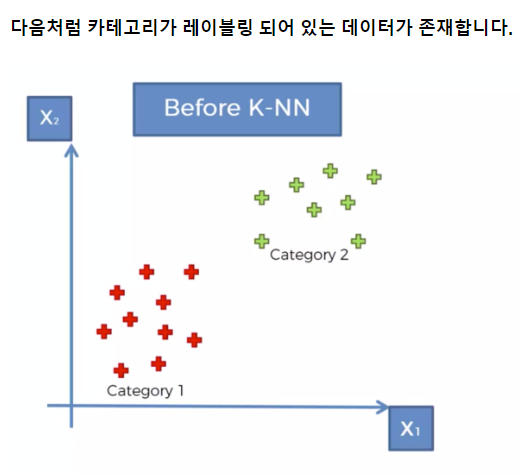


빨간색으로 분류한 이유는 가장 가까이 있는 데이터 n개가 빨간색이 더 가까웠기 때문이다.

다음과 같은 데이터셋이 있다고 할 때,
새로 입력된 데이터의 고객이 상품을 구매할 지 안할지에 대한 인공지능을 만들어보자.
# 데이터를 X와 y 로 분리
X = df.loc[:, "Age":"EstimatedSalary"]
y = df['Purchased']
# 피처 스케일링 ( 표준화 )
from sklearn.preprocessing import StandardScaler, MinMaxScaler
s_scaler = StandardScaler()
X = s_scaler.fit_transform(X)
# 학습용 데이터와 테스트용 데이터 분리
from sklearn.model_selection import train_test_split
X_train , X_test, y_train, y_test = train_test_split(X, y , test_size= 0.2, random_state= 3)위와 같은 전처리 과정을 거친 후 인공지능을 만들어보자.
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors= 3) #n_neighbor 은 디폴트 값이 5
classifier.fit(X_train, y_train)KNeighborsClassifier( ) 함수를 통해 K-NN 인공지능을 사용할 수 있다.
파라미터 값에서 n_neighbors 값은 가까이에 있는
데이터의 수를 몇개나 확인할 것인지의 대한 값이다. 디폴트는 5개!

from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)컨퓨전 매트릭스를 불러와 분류과정의 정확성을 알아보자.

90% 정확도가 나온 것을 알 수 있다.
# Visualising the Test set results
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1,
stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1,
stop = X_set[:, 1].max() + 1, step = 0.01))
plt.figure(figsize=[10,7])
plt.contourf(X1, X2, classifier.predict(
np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Classifier (Test set)')
plt.legend()
plt.show()차트로 확인해보면 다음과 같은 데이터 분포를 확인할 수 있다.
