# 새로운 데이터를 이미 fit으로 인코딩 정보를 담고 있는 ct를 그대로 이용하려면 transform 함X = ct.fit_transform(X)함수 이용
new_data = ct.transform(new_data)-신규데이터를 만들어둔 인공지능에 가져가 결과를 예측하는 방법에 대해 알아보자.
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X_train, y_train) #학습 끝
y_pred = regressor.predict(X_test)
##############################################
Error = y_test-y_pred
(Error**2).mean()
plt.plot(y_test.values)
plt.plot(y_pred)
plt.legend(['Real', 'Pred'])
plt.savefig('chart3.jpg')
plt.show()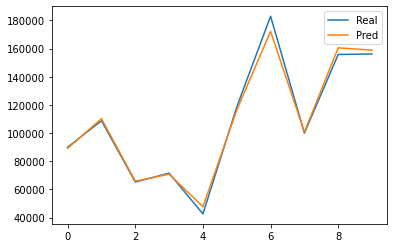
먼저 위와 같은 인공지능을 만들어둔 상황을 전제로 한다.
# R&D 비용은 220000달러, 운영비는 190000달러, 마케팅 비용은 500000달러이고
# 플로리다주에 있는 회사입니다.
# 이 회사의 수익을 예측하세요새로운 회사의 데이터로 수익을 예상하는 인공지능을 만들어서 데이터를 입력하려고 한다.
어떤 순서로 진행해야하는지 알아보자.

#1. 넘파이 어레이로 새로운 데이터를 만든다.
new_data = np.array([220000, 190000, 500000, 'Florida'])제일 먼저 넘파이 어레이의 형태로 새로 입력할 데이터를 만들어준다.
이 때, 리스트 속 데이터의 갯수는 X의 컬럼값과 같아야 예측이 가능하니 미리 확인해주자.
#2. 넘파이 어레이의 shape 을 맞춰준다. (X_train 의 컬럼 모양에 맞게) 1차원을 2차원으로 맞춰줄것
new_data = new_data.reshape(1, 4)두 번째로 1차원의 넘파이 어레이를 2차원 형태로 바꾸어주어야한다.
인공지능은 1차원 데이터를 인식하지 못하므로 꼭 reshape( )함수로 형태를 바꾸어주어야한다!
#3. 원핫인코딩으로 바꿀것.
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
from sklearn.compose import ColumnTransformer
ct = ColumnTransformer( [ ('encoder',OneHotEncoder(), [3] ) ] ,
remainder='passthrough' )
X = ct.fit_transform(X)
#위 문장은 인코딩을 지정하는 문장이고 새로운 데이터에 적용하는 함수는 밑의 문장을 이용하자세 번째로 인공지능 학습단계에서 인코딩된 컬럼이 있다면
새로운 데이터에서도 놓치지말고 꼭꼭 인코딩해주도록 하자.
# 새로운 데이터를 이미 fit으로 인코딩 정보를 담고 있는
ct를 그대로 이용하려면 transform 함수를 이용한다.
new_data = ct.transform(new_data)인공지능 학습에서 이용한 인코딩 방식으로 변경해주면 된다.
제일 중요한 점은 fit_transform 함수가 아니라 transform 함수를 이용해야한다.
fit_transform 함수로 적용하면 인코딩 정보가 다 바뀌게 되므로 주의할 것.

이제 기존의 인코딩을 거친 컬럼과 모습이 같아졌으니 인공지능에 적용할 수 있다!
new_data = ct.transform(new_data)# 만약 데이터가 float 이 아니면 float으로 바꿀것
new_data = new_data.astype(float)혹시 수치 데이터가 float 이 아닌 데이터가 있다면 astype() 함수로 꼭 float 으로 변경해주도록 하자.

이제 인공지능에 적용하면 예측결과가 정상적으로 나오는 것을 알 수 있다.
요약하자면
1. 넘파이 어레이로 신규 데이터 저장
2. 1차원의 데이터 2차원 형태로 변경
3. transform 함수로 fit_transform 함수에 적용된 인코딩 신규데이터에 적용하기
4. float 형태 확인하고 float으로 변경할 것
5. 미리 변수에 저장해둔 인공지능에 predict 함수로 인공지능에 적용하고 결과 확인하기!
위 인코딩 과정에서 fit_transform 함수와 transform 함수의 사용법을 알아봤는데
이는 Scaler 를 사용할 때에도 사용하게 되는데

방식은 인코딩 때와 마찬가지로 transform 함수로 fit_transform 함수로
scaler 가 적용된 변수와 같은 함수를 적용시키는 것이다.
fit_transform 함수와 transform 함수의 사용법은 scaler와 encoding 에서 모두 사용하므로 꼭 짚고 넘어가자.
'머신러닝 > 머신러닝 할 때 꼭 짚고 넘어갈 것' 카테고리의 다른 글
| WordCloud 에서 배경모양을 바꿔보자. (0) | 2022.05.10 |
|---|---|
| Grid Serch 에 대해 알아보자. (0) | 2022.05.09 |
| 머신러닝 전 꼭 알고 가자! - Feature Scaling 의 2가지 방법 : StandardScaler(표준화), MinMaxScaler(정규화) (0) | 2022.05.05 |
| 머신러닝 전 꼭 알고 가자! - 카테고리컬 데이터를 처리하는 방법 : 레이블 인코딩, 원 핫 인코딩(sklearn 라이브러리와 Pandas 라이브러리 이용 방법) (0) | 2022.05.05 |
| 머신러닝 전 꼭 알고 가자! - 카테고리컬 데이터를 확인하는 방법 (0) | 2022.05.05 |




댓글