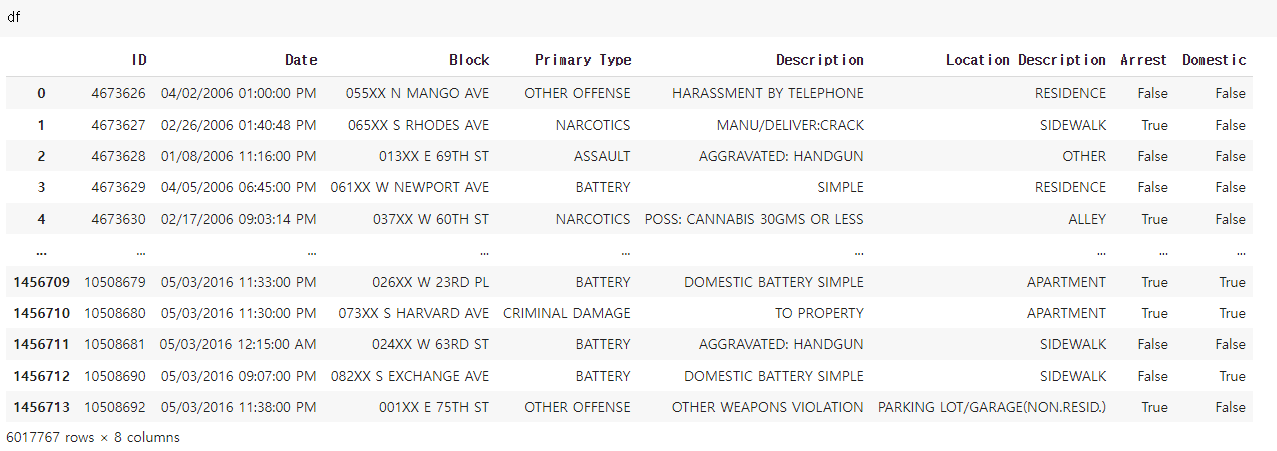
다음과 같은 데이터프레임이 있다.
우리는 날짜와 시간이 표시된 'Date' 컬럼을 기준으로 이를 기준으로 1년마다의 범죄 데이터를 열람해보려 한다.
이 때 어떠한 컬럼에 관하여 다른 컬럼을 비교하는 함수를 배운 적이 있다. 바로 groupby 함수이다.
언뜻 보면 비슷해보이지만 groupby 함수는 같은 데이터값을 가지고 있는 카테고리컬 데이터를 기준으로
데이터를 모아주기 때문에 날짜와 시,분,초가 모두 표시된 현재의 시간 데이터에서는 쓸 수 없는 함수이다.
그래서 우리는 인덱스를 기준으로 원하는 시간 범위별로 묶을 수 있는 resample 함수를 활용하여야 한다.
resample 함수를 사용하기위한 준비과정을 먼저 알아보자.
데이터나 인덱스를 시간대별로 묶는다는 이야기는 데이터가 단순 문자열이 아닌 시간 정보를 담고 있어야한다는 말이므로 우선적으로 시간데이터로 만들어주어야한다.

df['Date'] = pd.to_datetime(df['Date'], format = '%m/%d/%Y %I:%M:%S %p')
위 문장을 통해 시간 데이터에만 먹히는 dt 속성이 잘 작동하는 것을 볼 수 있다.
다음으로 먼저 말했다시피 resample 함수는 인덱스에만 적용이 되기 때문에 현재의 'Date' 컬럼을
# Date 컬럼은 그대로 두고 인덱스도 시간으로 정리하자는 의미.
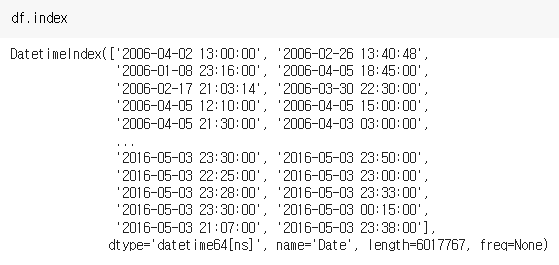
chicago_df.index = df['Date']기존의 Date 컬럼은 그냥 두고 인덱스만 현재의 Date 컬럼으로 씌워졌다.

이제 resample 함수를 사용할 준비를 마쳤다.
# resample 'Y' 는 년도다. 년도로 리샘플한 후, 각 년도별 몇개의 범죄 데이터를 가지고 있는지 확인한다. 'YS'는 연도의 시작일을 말함. 'Y'는 연도의 끝
# resample 은 시간간격을 재조정하는 것이다.
# 예시. '3T'는 3시간 간격으로 재조정
# resample 함수를 사용할 수 있는 이유는 인덱스이기 때문에
df_year = df.resample('Y').size()사용법은 다음고 같다. 인덱스와 Time Series 로 준비가 끝난 인덱스는
파라미터 값으로 묶고 싶은 시간 단위를 지정해 사용할 수 있다.
넣을 수 있는 인수값은 아래와 같다.

위의 결과를 보자면

다음과 같이 연 단위로 묶여 연 간 범죄 건 수를 알 수 있게 되었다.
df_month = df.resample('M').size()파라미터 값을 'M'으로 바꾸면

월 간 범죄 건 수를 확인할 수 있다.
'머신러닝 > 머신러닝 할 때 꼭 짚고 넘어갈 것' 카테고리의 다른 글
| Item based collaboration filtering 을 하기 위해, 데이터프레임의 corr() 함수를 이용한 correlation 과, min_periods 파라미터 사용법 (0) | 2022.05.12 |
|---|---|
| Pandas 데이터프레임의 pivot_table 함수 사용법 (0) | 2022.05.12 |
| DataFrame에서 문자열로 된 날짜 컬럼을 , datetime64로 변경하는 방법 / Pandas Series의 dt 속성 사용법 (0) | 2022.05.11 |
| read_csv 함수의 error_bad_lines = False 파라미터의 사용법 (0) | 2022.05.11 |
| Pandas의 groupby 함수 사용법 (0) | 2022.05.11 |




댓글