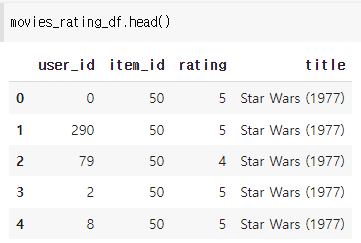
사람들이 관람한 영화에 대해 점수를 매긴 위와 같은 데이터가 있다.
이를 기준으로 어떤 영화를 시청한 사람에게 비슷한 영화를 추천하려고 한다.
하지만 지금의 경우는 어떤 유저가 영화 하나만을 시청한 게 아니라 수많은 영화에 대해 평점을 남겼을 수 있기 때문에 지금 상태에서 데이터를 처리하기엔 무리가 있다.
그 때 사용하는게 Pandas 의 pivot_table 함수이다.
df = movies_rating_df.pivot_table(values= 'rating', index= 'user_id', columns= 'title', aggfunc= 'mean')
# aggfunc의 디폴트 값은 평균값 mean
# 피봇 테이블의 인덱스와 컬럼. 밸류에 원하는 값을 넣을 수 있도록 생각해보자.판다스 데이터프레임에 사용하는 함수로 파라미터로 values, index, columns 그리고 aggfunc 의 값을 지정해 사용한다.
원래 데이터프레임에 있는 컬럼의 값들을 파라미터로 지정하고 aggfunc 의 경우 (mean, sum, count ...) 과 같은 인수를 넣을 수 있다. 디폴트 값은 mean 이다.
위 문장으로 통해 만들어진 pivot_table은 다음과 같다.
제일 중요한 것은 values 와 index, columns 에 어떤 컬럼이 들어가야할지 잘 생각해야하는 것이다.

'머신러닝 > 머신러닝 할 때 꼭 짚고 넘어갈 것' 카테고리의 다른 글
| Item based collaboration filtering 을 하기 위해, 데이터프레임의 corr() 함수를 이용한 correlation 과, min_periods 파라미터 사용법 (0) | 2022.05.12 |
|---|---|
| Time Series 데이터를 처리할 때 사용하는 resample 함수의 사용법과,이 함수를 사용하기 위해 인덱스를 설정하는 방법 (0) | 2022.05.12 |
| DataFrame에서 문자열로 된 날짜 컬럼을 , datetime64로 변경하는 방법 / Pandas Series의 dt 속성 사용법 (0) | 2022.05.11 |
| read_csv 함수의 error_bad_lines = False 파라미터의 사용법 (0) | 2022.05.11 |
| Pandas의 groupby 함수 사용법 (0) | 2022.05.11 |




댓글